
1図 ファイル構造
ソート済みのマスタファイル(master file)をこれもソート済みの トランザクションファイル(transaction file)に基づいて更新するという手続きは マッチング(matching)と呼ばれ、 もっとも基本的な事務処理処理の1つですが、 汎用機やオフィスコンピュータの世界では、 COBOL による煩雑なプログラムをいちいち書く必要があります。
upd はこのマッチングのプログラミングを簡単にする目的で開発された 極めて有効なツールで、 マスタファイルとトランザクションファイルの2つを読み、 それらのキーが一致した場合(MATCH)と一致しない場合(MONLY,JONLY) の振り分けを自動的に行なうため、 利用者はこれらに対応する手続きだけを awk とほぼ互換の命令で記述すればよく、 アップデート処理そのものは意識しなくても済むようになっています。
以下、upd によるマッチングの手法を具体的に述べますが、upd そのものの詳細に ついては upd のマニュアルをご覧ください。
最初に、マッチング処理の対象となるファイル構造の要点を解説します。
1群のレコード (record)の集まりをファイル(file)と呼びます。 レコード(記録)は、 特定の相手先の住所等、1件分のデータです。レコードとレコードの区切りは、 レコードセパレータ(RS - Record Separator)と呼ばれ、 通常、改行文字(LF)を使用します。 これは、1行1レコードの形式が人間にも見やすく、 コンピュータにとっても無駄がないためです。
1図 ファイル構造
レコードは、通常、いくつかのフィールド (field - 項目)から構成されます。 フィールドというのは、住所、電話番号、相手先の名前といった、 データの最小単位です。 フィールドとフィールドの区切りは フィールドセパレータ (FS - Field Separator) と呼ばれ、通常、空白かタブ文字を使用しますが、 フィールド中に空白文字を含む場合は、コロン (:) を使うのがよいでしょう。 レコードの最後のフィールドには、フィールドセパレータをつけません。 レコードセパレータが区切りになるためです。
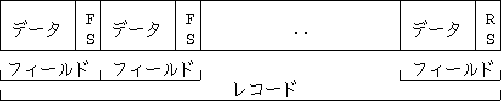
2図 レコード構造
フィールドそのものが、いくつかの サブフィールド(Sub-Field)からできていることも良くあります。 例えば、人の名前は姓と名の2つから構成されるといった具合です。 このようなケースでは、 2次フィールドセパレータを使って、フィールドをさらにサブフィールドに分割します。 1次フィールドセパレータに空白文字かタブ文字、 2次フィールドセパレータにはコンマ(,)を使うことが多いのですが、 データそのものに空白文字を必要とする場合は、 1次フィールドセパレータとしてコロン (:) を使い、 2次フィールドセパレータとして空白文字を使用すると、きれいにまとまるこ とが多いようです。
例えば、住所録のケースでは、氏名を姓と名の2つのサブフィールドに分ける他、 小さなラベルに長い住所を折り返してプリントできるように、住所そのものも2, 3のサブフィールドに分割することが良く行なわれます。
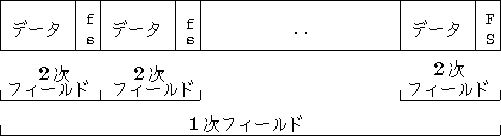
3図 2次フィールド
例えば、この形式のレコードは、次のようになります。
102:モガミデンセン:399-6461 長野県塩尻市宗賀469:モガミ電線(株):0263-52-0131郵便番号の後に、2次フィールドセパレータがあります。
レコードセパレータを空白行とし、 改行文字をレコードセパレータとしたレコードを マルチラインレコードと呼び、 アプリケーションによっては、大きな威力を発揮します。 人間に見やすいのが最大の利点で、コンピュータにとっても無駄がありません。 1行1レコードの形式が面白くない場合は、検討すべきです。 UNIX の awk 等のコマンドでは、FS に空文字列 ("") をセットすることにより、 マルチラインレコードを扱えるようになっています。
データをリアルタイム(即時処理)で更新しなければならない場合は、ファイル全 体でなく特定のレコードやフィールドだけを書き換えられるように、フィールドの 大きさを予想される最大値にした、いわゆる固定長レコード形式にする必要があ ります。つまり、普段は使用しない無駄な空白を代償として、即時更新が可能にな るわけです。リアルタイム処理や対話型の処理には大きな魅力がありますが、その 代償も大きく、どうしても必要な場合に限るべきです。例えば、対話型の処理は、 自動化ができません。
なお、COBOL を主力言語とする、オフィスコンピュータや汎用機では、 未だにこの固定長レコード形式が使われていて、 汎用機のデータを UNIX 流の可変長データに変換すると、 20 % 程度になってしまうのが普通です。 節約したディスクのスペースを金額に換算すると、アッと驚く量になります。
事務処理の最も基本的なパターンのひとつが マッチング(matching)と呼ばれるもので、 これは4図のように既存のマスタファイルとトランザクションまたはジャーナル と呼ばれる入力ファイルから、更新済みの新しいマスタファイルを出力する バッチ(batch - 一括)処理になります。
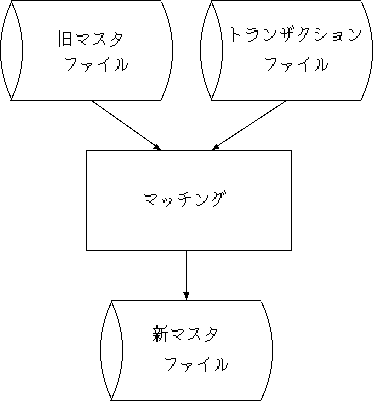
4図 アップデート処理
マスタファイルはレコードの対象を識別するための「 キーフィールド」(key field) と「累計」や「残」といった絶えず更新される「管理データ」に加えて、 時おりメンテナンスすれば済む「固定的なデータ」フィールドから構成され、 トランザクションファイルは更新の対象を示すキーフィールドと「更新データ」 からできています。 5図と6図がその簡単な例です。

5図 簡単な在庫のマスターファィル

6図 簡単な在庫のトランザクションファイル
管理というのは「残と合計の管理」 と言い切れるほどこの2種類のデータが大切で、残が時間軸の横断面データ、 合計がその時間軸での経過や原因になるのが普通です。
この品名等、管理対象を識別する名前としては、入力や機械的処理が容易な、数字 ないしは英数字の組合せによる「コード 」(code)を使うのが普通で、 人間向きの名前や詳細な属性等は「コメント(注記事項))」フィールドに入れる ようにします。
マスタ、トランザクションともに、 キーフィールドは昇順にソート しておかなければなりません。 また、マスタファイルのキーには重複があってはなりません。 トランザクションの方は、 業務の性格によって、キーの重複がある場合とない場合の両方があります。
この状態からスタートしてマスタとトランザクションファイルを順次入力し、 トランザクションのキーに対応するマスタファイルのデータを更新しつつ、 更新済みのマスタファイルを出力して行くのがマッチング処理になります。 対応するトランザクションのないマスタファィルは、そのまま出力します。 すなわち、データの更新が行なわれません。マスタに対応しないトランザクションは、 エラーデータとして処理されるのが普通です。
以下、最も基本的な、トランザクションにキーの重複のない場合について、upd の 具体的な使用例を述べます。
5図のマスタを6図のトランザクションで更新することを考えます。 マスタファイルの名前を data.m 、 トランザクションファイルの名前を data.j としましょう。 キーフィールドすなわち品名がマッチ(一致)した場合は、 入庫累計と残にそれぞれ入庫数量を加え、 トランザクションに対応しないマスタはそのまま出力、 マスタに対応しないトランザクションはエラー処理というわけで、 次のようなプログラムができあがります。
# プログラム 1 - 1対1のマッチング
upd '
MATCH { # マッチした場合
$2 += ?2
$4 += ?2
print $0
}
MONLY { # マスタのみの場合
print $0
}
JONLY { # トランザクションのみの場合
print "アンマッチ:", ?0
}
' data.m data.j
$0 はマスタファイルのレコード全体、$1, $2, .. はそれぞれ1番目、 2番目のフィールドです。 同様に、?0 はトランザクションファイルのレコード全体、 ?1, ?2, .. はそれぞれトランザクションファイルの1番目、 2番目のフィールドになります。 フィールドセパレータは デフォルトでは空白文字(SPACE)とタブ文字 (TAB)になっていますが、 BEGIN セクションで
FS - マスタファイルのフィールドセパレータ JFS - トランザクションファイルのフィールドセパレータ OFS - 出力ファイルのフィールドセパレータで指定することもできます。「print $0」の $0 は省略できますが、このテキスト では、何を出力させているかをはっきりさせるため、明示することにします。
この例では、トランザクションにキーの重複があるとうまくゆきません。 重複した2つ目以降のトランザクションを読んだとき、 マスタの方は次に進んでしまうため、 重複したトランザクションレコードがエラーになってしまいます。 在庫管理のシステムで発生するデータとしては、 トランザクションにキーの重複がある方が普通ですが、給与計算等、 トランザクションにキーの重複のないシステムも多く、 1対1のマッチングは事務処理の最も基本的なものの一つです。
キーの重複のあるトランザクションを処理する場合は、 「MATCH」セクションではデータの更新だけを行い、 「FLUSH」セクションで更新されたマスタファイルのデータを書き出します。 「FLUSH」セクションが実行されるのは、マスタ・ファイルを読んだ後、 次のマスタファイルを読む直前かファイルの終りに達したときです。例えば、 プログラム 2 のようになります。
# プログラム 2 - 1対nマッチング
upd '
MATCH {
$2 += ?2; $4 += ?2
}
FLUSH {
print $0
}
JONLY {
print "アンマッチ:", ?0
}
' data.m data.j
7図のトランザクションレコードの形式では、入庫だけしか処理できません。 入出庫の両方を処理するには、次の3つの方法があります。
第一は、7図と同様のトランザクションレコードを出庫用についても作成し、 入庫は入庫、出庫は出庫と別々に処理する方法です。会社組織やシステムによっては、 たいへんうまく適合します。
第二は、7図のように、数量が入庫であるのか出庫であるのかを区別するための、 区分コードのフィールドを追加する方法です。 区分コードとしては、1ー2桁の数字や文字が良く使われます。例えば、
1 入庫 2 出庫といった具合いです。
7図 入出庫データ
この形のレコードを upd で処理する場合は、例えば、プログラム 3 のようになり ます。
# プログラム 3 - 区分コードによる入出庫データの同時処理
upd '
MATCH {
if (?2 == "1") { # 入庫
$2 += ?3; $4 += ?3
}
else if (?2 == "2") { # 出庫
$3 += ?3; $4 -= ?3
}
else
print "区分コードデータ・エラー:", ?0
}
FLUSH {
print $0
}
MONLY {
print $0
}
JONLY {
print "アンマッチ:", ?0
}
' data.m data.j
このように、 データそのものとデータの種類をあらわす区分コードを組み合わせて使う手法は、 コンピュータによるデータ処理では頻繁に使われます。
第三の方法は、 トランザクションに入庫と出庫の2つのフィールドを用意するものです。 いすれか一方のデータしかない場合は、残りのフィールドはダミーとして、 「0」等を入れておきます。

8図 入庫と出庫の二つのフィールドを持つデータ
ダミーの技法もコンピュータの分野では、極めて重要です。
マスタファイルのデータをトランザクションファイルのデータによって 「 更新」(up-to-date)する以外に、 マスタファイルそのものを「更新 」(updating)することも日常業務のひとつです。 これは、在庫管理なら、新しい品目の追加とか、旧品目の削除、 品名の変更といった具合で、
追加、削除、変更の3つのパターンがあります。
これらの3つを、通常、マスタファイルの メンテナンス(maintebance)と読んでいますが、 処理そのものの論理や手法は、すでに述べた1対1のマッチングとまったく同じで、 技術的にはマッチング処理と同時にできないことはありません。 ただ、通常このメンテナンス(変更)とアップデート(更新)の処理は 別々に行われるのが普通で、理由は次のとおりです。
1. エラー検出能力が高くなる。 2. マスタ変更は重大で頻度も低いため、管理者のみに制限するほうが良い。
ファイルのメンテナンスを行なうためのトランザクションの1例を示します。

9図 マスタメンテナンス用トランザクションの例
区分コードは、例えば、次のようになります。
1 追加 2 変更 3 削除追加の場合はデータとして全レコードが必要ですが、変更の場合は一部のフィール ドだけを書き換えれば済むことが多く、変更の箇所(フィールド)と変更内容の組 合せで指定することも良くおこなわれます。削除の場合はデータを省略するか、ダ ミーとします。
1対1のマッチングについて、upd の動作をフローチャートで示します。「FLUSH」 セクションを記述して1対nのマッチングを行う場合は、「MATCH」セクション実行 後次のトランザクションが現在のマスターと一致しなくなるまでマスターを読まず、 すでに入力済みのマスターレコードを使用します。
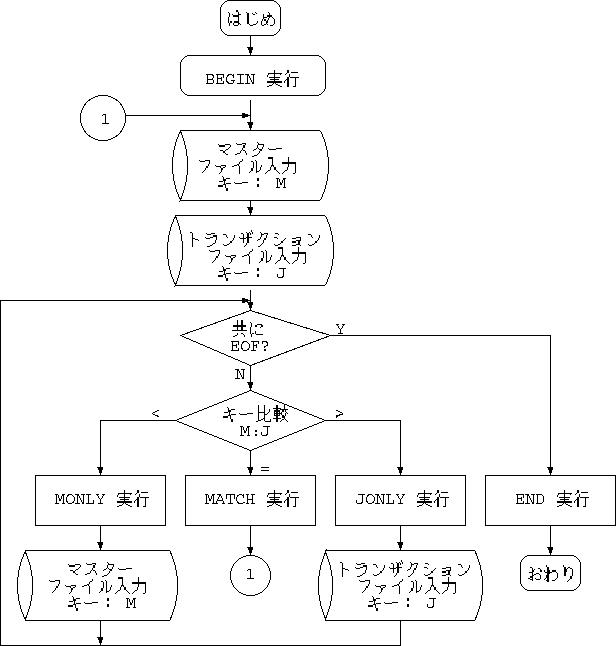
「upd」のアイデアは 1960 年台の紙テープベースのオフィスコンピュータを使った ときに得られたもので、当時はアセンブリ言語や COBOL のプログラムジェネレータ として実現しました。その後、 System III の Unix に移行したとき、現在の awk 互換仕様に書き換えました。
Kouichi Hirabayashi, 1982